Item-Based Collaborative Filtering With Haskell
Introduction
Item-based Collaborative Filtering is an algorithm that computes item similarity based on ratings or interactions by users. With this algorithm, we can recommend users the items they might like by computing the similarity between the items they actually like and other items they haven’t bought or interacted with yet. This project implements the Item-based Collaborative Filtering algorithm with Haskell. Different types of parallelizing strategies are explored and analyzed.
Problem Formulation
In this project, the MovieLens dataset is used. The MovieLens dataset provides 100000 ratings (943 users, 1682 movies). The program will compute the similarities between the items, predict the rating of each of them, and recommend a list of items to the specified user. The input to the program contains the user’s id, the number of items that we wished to used to predict the ratings with, and the number of items that we want to recommend to the user. The output of the program will simply be a list of item ids.
Implementation
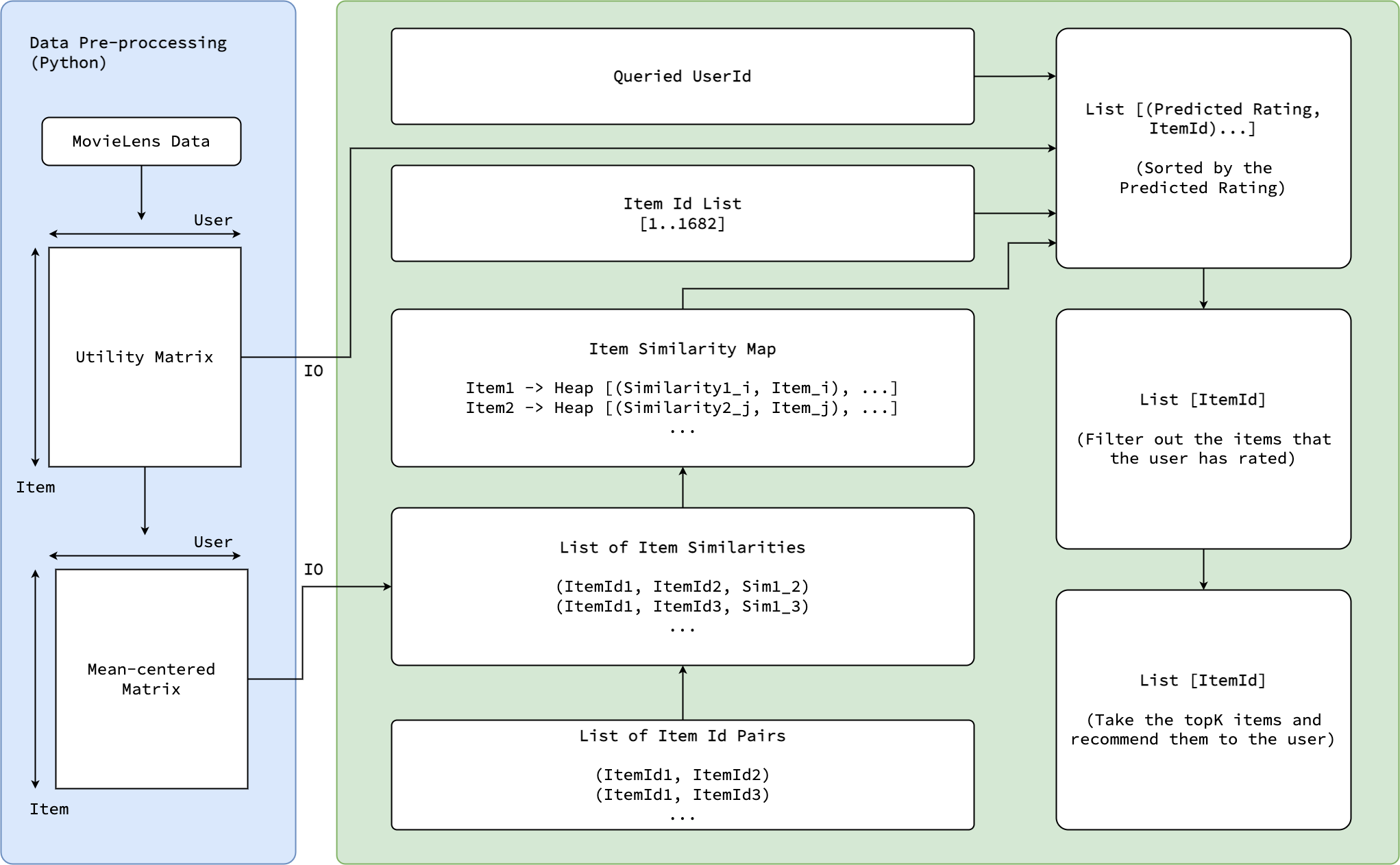
- First, a Python program is used to read and preprocess the MovieLens data into two text files. One of them is the original utility matrix, and the other one is the mean-centered matrix. Both files contains 1682 rows and 943 columns.
- The Haskell program reads the matrix text files into two Data.Matrix.
- A list of item id pairs are generated. This is used to compute the similarity later. Example look of the lis [(1, 2), (1, 3), ..., (1681, 1682)]
- A function that computes the cosine similarity between items will take the list generated in the last step and computes the cosine similarity between each items. After the com- putation we will get a list of tuples with the items’ ids and the similarities between them: [(item1, item2, similarity1,2)...]
- Obtaining the item similarity map: When we are computing the predicted score for an item, we need to be able to access the items that are highly similar to it quickly. A map is suitable in the situation. With the list of item pairs and similarities in the last steps, we can initialize an item similarity map. The key of the map is the item’s id, and the value of the map is a Heap that that stores tuples of a similarity value and an item id.
- For the queried user, we predicted the ratings of all 1682 items and return a list of type [(Rating, ItemId)]
- The list [(Rating, ItemId)] is then sorted by the rating.
- Items that are already rated by the user will be filtered from the list obtained in the previous step. The rating is also removed from the list, so we are only getting a list of item ids from this step.
- For the final step, the top k items are recommended to the user. k is also a user input for the program.